之前写过一篇电影数据分析的文章”豆瓣13万电影数据统计与分析“,引起了一些读者的关注,并且在后台咨询我是否可以分享下源码。为了满足大家的需要,我在五一期间将源码略作整理了下,并从中筛选了几个绘图源码在这里分享给大家,如有疑问,可在评论区留言。特别说明下,文中分析的数据来自电影数据集Moviedata-10M中的movies.csv文件,需要的童鞋可以按照官方的说明进行下载即可。
准备工作
在进行源码分享之前,这里先说说我们的运行环境吧,我是使用jupyter进行实验的(强烈推荐),python 3.6版本,依赖的相关库如下:
- pandas
- matplotlib
- seaborn
- numpy
- WordCloud
- imageio
- squarify
如果对上面的库不了解或者不会安装的,请自行查阅,这里就不一一细说了。
数据加载
由于文件是csv文件,所以加载数据只需要使用python里面的pandas库即可,采用pandas中的read_csv就可以将csv中的数据加载到内存中,代码如下:
1 | import csv |
统计分析
在豆瓣13万电影数据统计与分析一文,我从不同的维度对电影数据进行了分析,在这里不会将全部的源码分享出来,但是会将核心内容贴出来。
按上映年份统计电影
首先导入相关依赖库,主要是matplotlib,如下:
1 | import matplotlib.pyplot as plt |
下面这几行代码是为了解决图表中的中文乱码问题,仅供参考:
1 | #解决matplotlib 乱码 |
在绘制图表之前,我们需要对数据进行处理,构造我们需要的数据格式:
1 | #如果year字段为空,就从release_date进行截取 |
得到2020年之前的电影之后,我们再分组统计每年上映的电影数量
1 | year_grp = movies.groupby("year2").size().reset_index(name="num") \ |
接着,按照年份和上映的电影量进行绘图,首先分享下散点图的绘制方法,代码如下:
1 | import seaborn as sns |
draw_stripplot方法是可以共用的,如果其他的聚合数据生成了,也可以调用上面的方法。得到的图表如下所示:
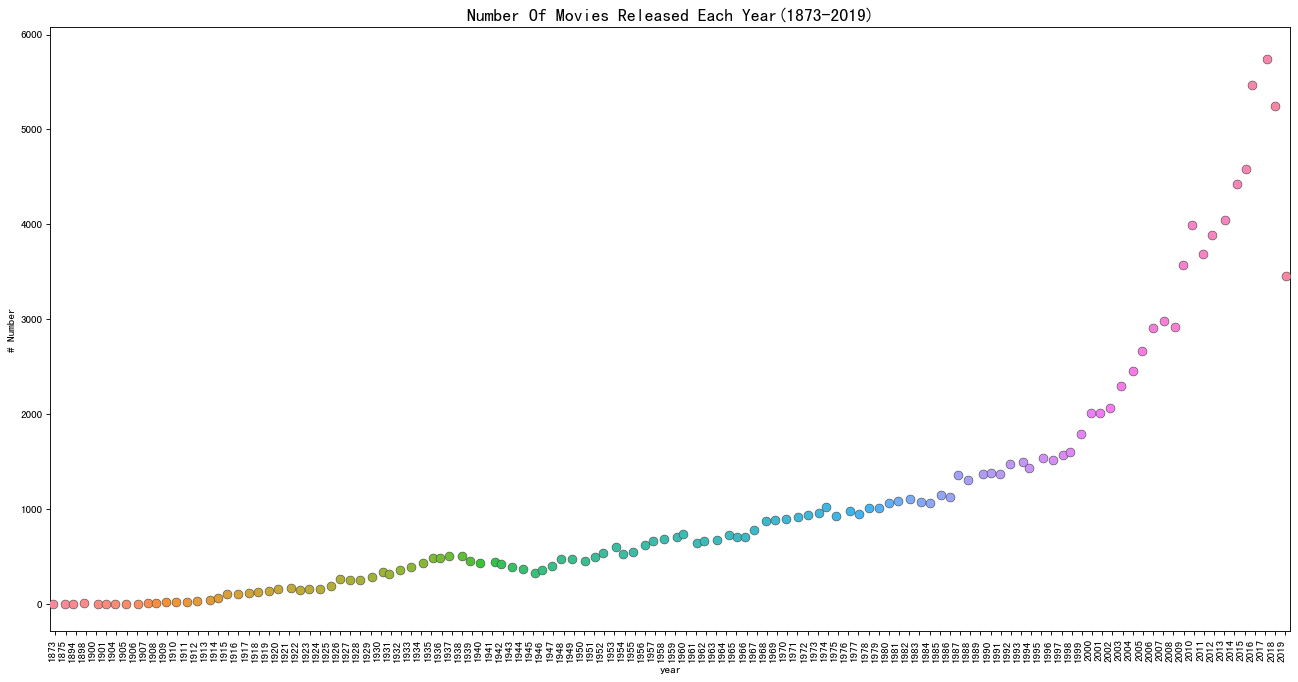
按评分统计电影
首先分组统计出每个评分的电影数量
1 | df = movies.groupby('douban_score').size().reset_index(name='counts') |
采用movies[movies["douban_score"] > 0]["douban_score"].mean()可以统计出电影的平均得分为6.63。
接着编写柱状图绘制函数,代码如下:
1 | #柱状图 |
将数据采用上面别写函数进行渲染:
1 | draw_barplot(df, df.douban_score, df.counts, |
得到的柱状图如下所示:
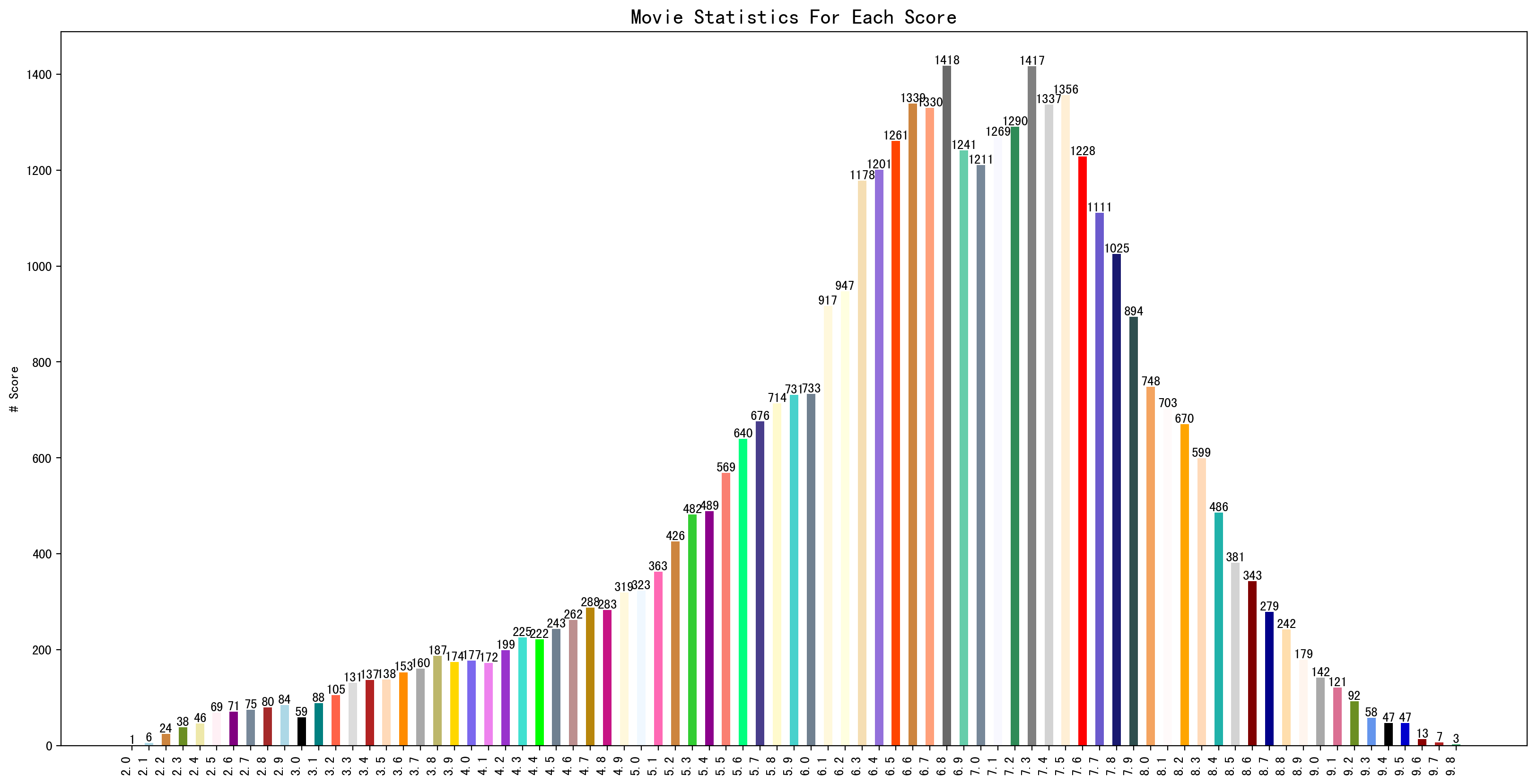
按照国家进行统计
首先根据国家进行聚合,
1 | movies_regions = movies |
然后调用draw_barplot函数即可:
1 | draw_barplot(df, df.regions, df.counts, |
结果图如下:
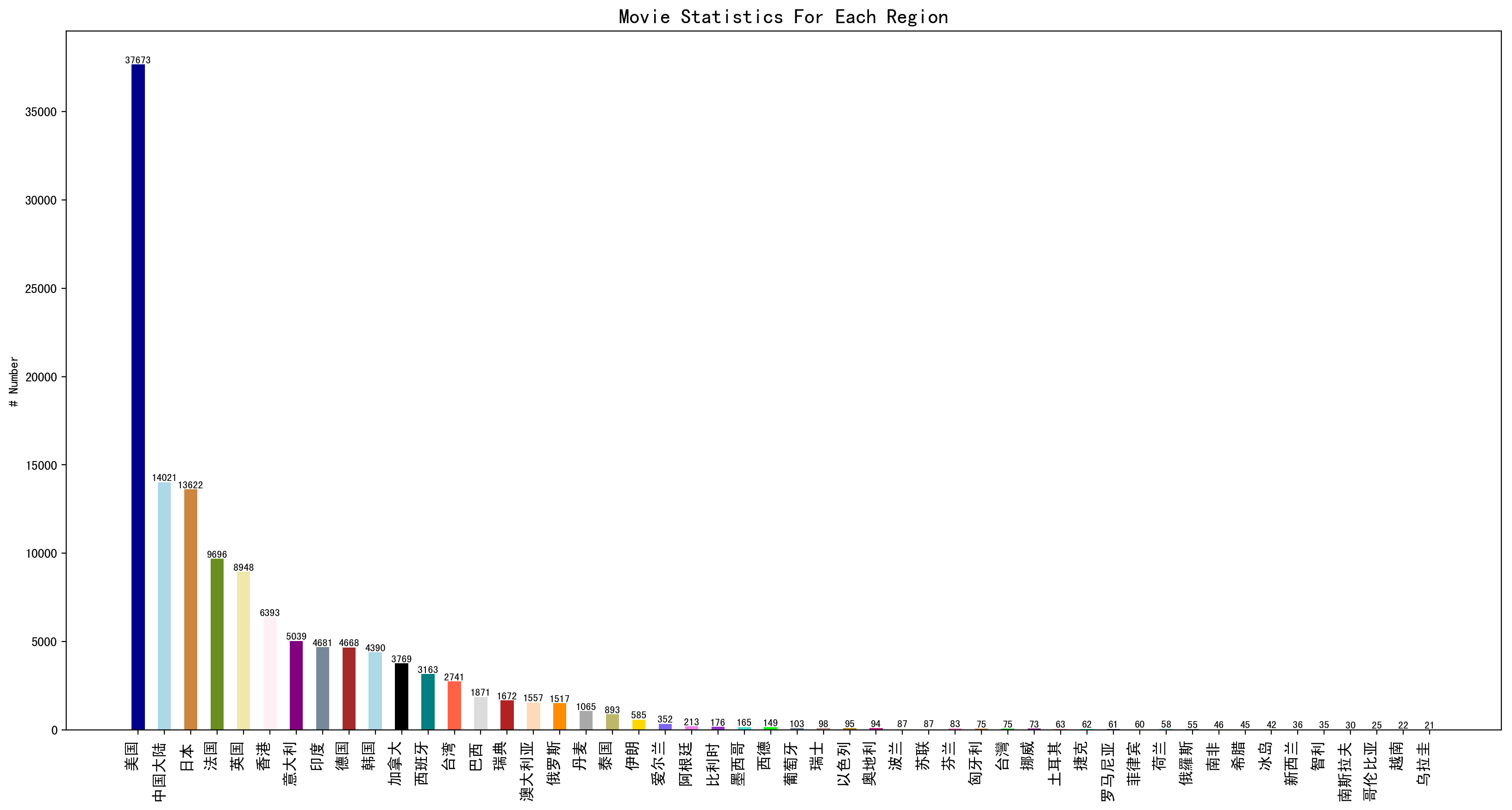
按语言进行统计
数据构建
1 | df = movies.groupby('languages').size().reset_index(name='counts') |
绘制饼状图,并进行渲染:
1 | import matplotlib.pyplot as plt |
结果图如下:
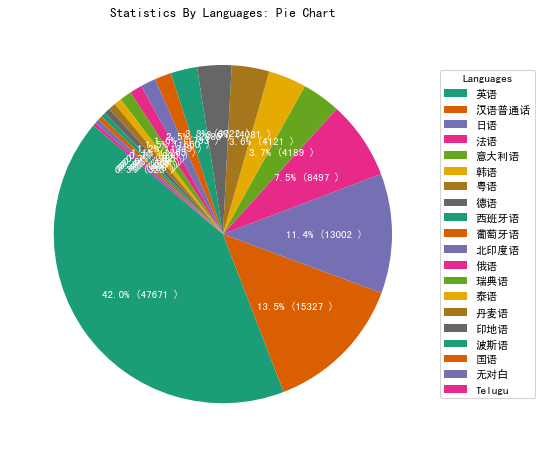
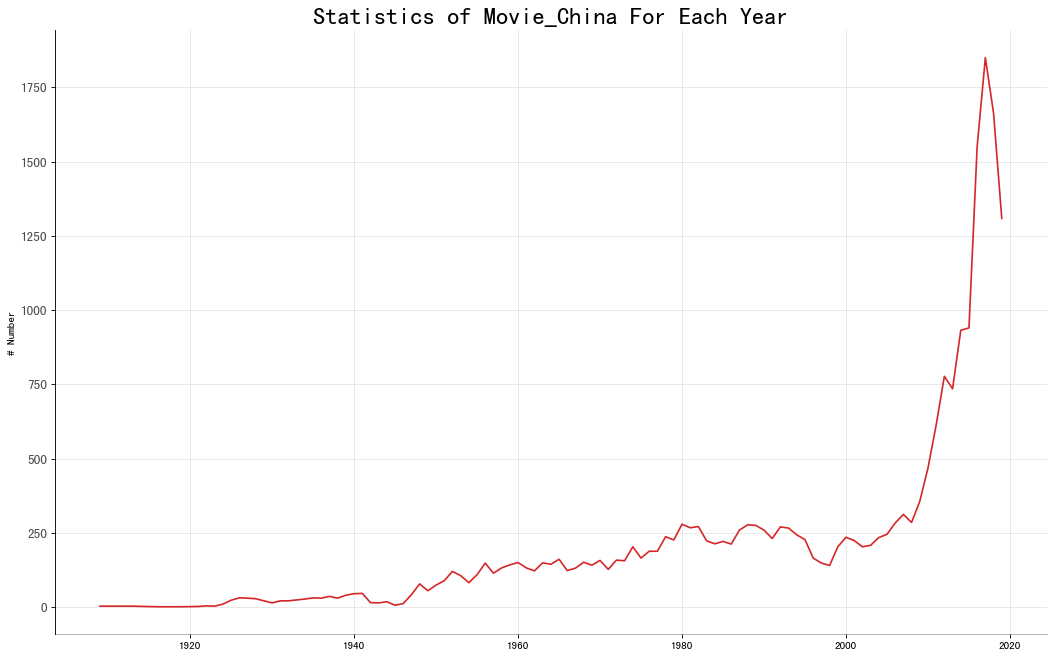
对中国的电影进行分析
同理,首先构造数据格式:
1 | movies_china = movies[movies.regions.str.startswith("中国") | \ |
接着绘制线性趋势图:
1 | def draw_plot_liner2(df, df_x, df_y, |
最后得到的趋势图如下:
如果需要渲染多个国家进行对比,只需要将多个国家的数据进行聚合然后一个个绘制到图上即可。
词云
电影类型词云
如果想要绘制类型词云,需要上面提到的WordCloud库。
1 | from wordcloud import WordCloud |
当具备这些之后,我们首先要准备数据,取出电影标签,然后进行词频统计,
1 | object_list = movies.genres.tolist() |
接着调用WordCloud库进行分析
1 | b_mask = imageio.imread("./data/bg_my.jpeg") #如果运行到这里找不到图片,请自行替换图片即可 |
如果词库比较大的话,时间需要久一点,最后得到的图片如下:

标签词云也是类似的,只需hexo要重新渲染下数据即可。
结束语
文章共介绍了散点图、线性图、柱状图、饼状图、词云这几个核心图表的绘制,只要下载了相关库,那么构造出相应的数据格式之后,代码可以直接运行,后续我会考虑以jupyter文件分享出来,大家可以关注下我的公众号:【斗码小院】,相关内容会第一时间发布到公众号中,如果相关问题,也可以在公众号的“关于小院”一栏进行留言。